意见词提取作为方面级情感分析(Aspect-based sentiment analysis, ABSA)的一个关键子任务,旨在从文本中辨别与特定方面相关联的意见词。早期意见词提取工作主要集中在如何手动提取经过细化的特征,并将这些特征输入到支持向量机等分类器中,后来一些研究人员开始采用自动特征提取方法实现意见词提取,例如,通过句法关系自适应地将上下文词中的情感传播到方面项。其他则构建了一个无需进行句法分析的特征提取器,以识别指定方面的相关特征。随着深度学习技术发展,为更进一步进行语义建模,有文献提出使用与目标相关的长短期记忆网络(Long short-term memory,LSTM)来进行自动特征提取。HE等则将注意力机制(Attention mechanism,AM)与LSTM结合应用于方面级情感分析,以聚合上下文特征进行意见词提取。此外,为了更好关注单词间的句法联系,处理更复杂的句子结构,一些研究也开始将依存句法树、成分句法树和意见句法树等句法树引入到意见词提取中。
从食品品评文本中进行感官分析与上述意见词提取研究类似,两者都需要从文本中自动提取出与某一方面相关的特征描述词,并分析这些词与方面之间的关系。因此,意见词提取中的一些技术和方法可以为食品感官分析提供启发和支持。不过,在食品感官分析领域,感官信息既包括甜、酸、苦、咸等基本味道,也包含质地、口感润滑度、粘稠度等多方面信息;同时每一种感官信息都有自己的强度属性。例如某一款饮料的甜度较强,但是酸度较弱,在这种情况下仅提取出酸和甜无法细粒度刻画其感官评价。这导致已有的意见词提取研究难以直接应用在食品感官分析领域,无法直接捕捉食品感官评价中的感官词及对应的感官强度、难以对感官强度进行细粒度处理。
本文旨在针对食品品评文本进行细粒度感官分析,基于方面级意见提取提出一种基于强度注意力和强度句法树的细粒度感官分析模型FGSAM-01,构建专用的食品感官分析数据集,并在该数据集上对模型进行实验验证。
细粒度感官分析模型描述
为了更好挖掘食品品评文本实现对食品感官的细度分析,本文提出一种细粒度感官分析模型FGSAM-01。在FGSAM-0I中,提出一种强度注意力动态调整对输入序列不同部分的关注程度以进一步强化对强度词的表示能力;同时,提出强度句法树进一步将强度词关联到相应感官词,以更准确描述感官词与强度词关系,进而从整体上提升食品各个方面感官属性的分析精确度,图1展示了FGSAM-0l的整体框架,主要由4部分组成:文本编码模块,用于对输入的食品品评文本序列进行编码;强度注意力模块,用于强化对文本序列中强度词的表示;强度句法树融合模块,用于分析强度词和感官词的关联性;分类器,将强度词转化成对应的强度数值。
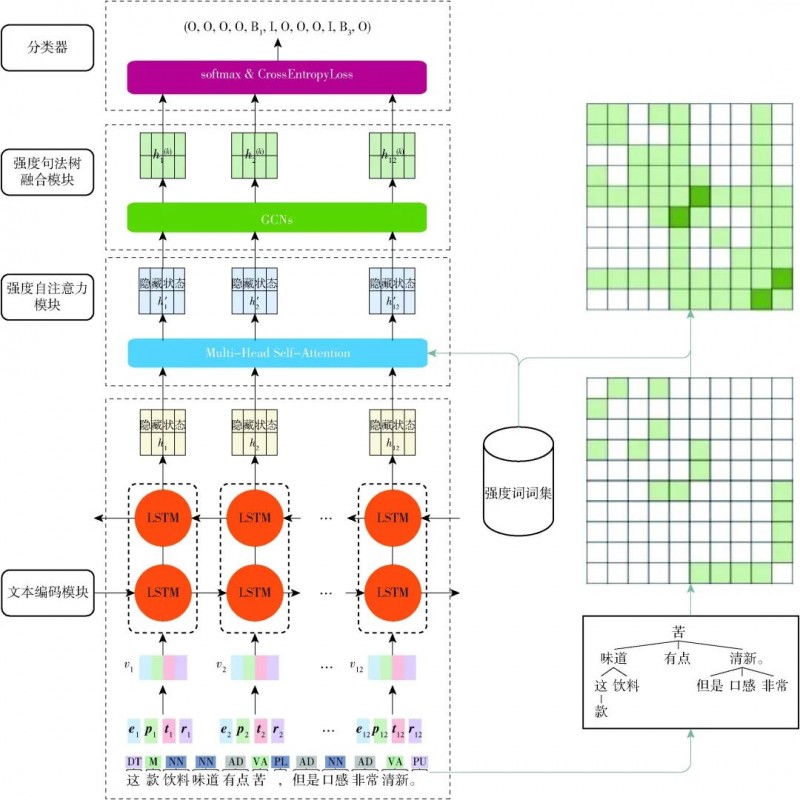
01问题定义
对于给定的食品品评数据集,每一个数据样本可以表示为S={w1,w2,…,wn},其中n为句子中的token数,每个句子会有一个或多个方面项wasp∈S,对某个方面项可以通过B/I/O标注方式提取句子中的感官词wopn∈S,并以B0、B1、B2和B3表示wopn的感官强度,分别代表无感官强度和低、中、高感官强度。
02文本编码模块
文本编码模块的任务是将数据集中的品评文本转化为相应的向量表示,以便后续模型处理。对一个包含n个token的句子S,从词嵌入、位置嵌入、词性嵌入和依赖关系嵌入4个方面对其进行文本嵌入,以更全面建模和理解输入的品评句子。
03强度注意力模块
为进一步实现细粒度感官分析,提取品评文本中的感官词及其相应强度信息,借鉴深度学习中的多头注意力机制,本文提出在模型中增加强度注意力模块。该模块通过反向传播学习权重矩阵动态调整对品评文本中不同词的关注程度,以进一步强化对强度词的关注,提高分析准确率。
04强度句法树融合模块
在通过强度注意力模块提高对强度词关注程度后,为更好借助句法结构将感官词和强度词进行关联,本文基于传统的依存句法树设计一种强度句法树(lntensity syntax tree),根据预定义的强度词集合,对与强度词相关的依存关系进行加权处理。05分类器在模型最后阶段,本文采用了与文献类似的方法进行分类与优化。模型首先将最后一层GCN的输出表示H应用于线性层,然后使用softmax函数对其进行标准化,以输出S中每个token在集合{B,I,O}上的概率分布以及强度。在训练过程中,通过使用交叉熵损失函数来最小化训练集中文本的预测误差。
最终,模型会输出格式为[[BeginIndex, EndIndex], Intensity]的结果,分别标识感官词及其强度词的起始和结束位置以及具体的感官强度。通过将这些预测结果与特定的方面进行关联,并进行汇总与分析,即可得到最终的食品感官分析结果。
实验数据集
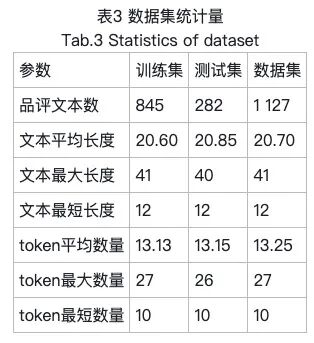
本文以北京林业大学生物学院的风味碳酸饮料PM&FP(Project mapping & Flash profile)感官调研结果为基础,构建了专有的食品感官分析数据集。该数据集总共包含180名消费者共1 127条有效评论品评文本,按照3∶1的比例划分为训练集和测试集。具体的数据集特征见表3。在对品评文本进行数据标注时,文本分词、句法解析以及词性标注均通过Stanford CoreNLP完成,而方面词、感官词和感官强度则由实验人员手工标注以支撑模型训练和测试。
同时,本文将感官词和强度词的提取任务定义为序列标注任务,并改进了原有的BIO标注以标识强度信息。具体来说,会将句子中的token标记为感官词的开始(B0、B1、B2、B3分别代表无强度信息和低、中、高强度信息)、中间或结尾(I),或者不是感官词(O)。数据集标注示例见表4。
更多精彩内容请见《基于细粒度方面级意见提取的食品感官分析研究(下)》!